Register im Kontakt
Registers in Contact
Register im Kontakt: sprachliche Entwicklung wissenschaftlicher Fachregister
(gefördert vom DFG 2010 - 2013)
Das Thema dieses Projekts ist die sprachliche Entwicklung der funktionalen Variation in hochspezialisierten wissenschaftlichen Bereichen. Das Projekt zielt darauf ab, domänenspezifische Variation zu analysieren, die durch Registerkontakte in einem Korpus englischsprachiger wissenschaftlicher Texte entstanden ist. Unser Fokus liegt auf wissenschaftlichen Domänen oder Disziplinen an den Grenzen der Informatik (z.B. Computerlinguistik, Bioinformatik). Die zentrale Frage des Projekts lautet: Mit welchen sprachlichen Mitteln wird eine unverwechselbare Identität der durch Registerkontakt entstandenen Disziplinen geschaffen? Aus sprachwissenschaftlicher Sicht ist der Untersuchungsgegenstand ein Phänomen des jüngsten Sprachwandels, der nicht mit dem Sprachsystem, sondern mit dem Sprachgebrauch zusammenhängt. Zu diesem Zweck verwenden wir ein bereits existierendes synchrones Korpus (DaSciTex), das aus englischen wissenschaftlichen Texten der frühen 2000er Jahre besteht, und erweitern es diachron (1970er/1980er Jahre) zum SciTex-Korpus (English Scientific Text Corpus). Unser Ziel ist es, das Korpus zur empirischen Analyse der linguistischen Entwicklung ausgewählter wissenschaftlicher Register zu nutzen. Methodisch basiert die Studie auf der englischen Registertheorie. Wir verwenden sowohl bereits in der Korpuslinguistik etablierte Methoden als auch neue probabilistische Methoden zur Identifizierung von Textähnlichkeiten.
Aufbau und Größe des Korpus
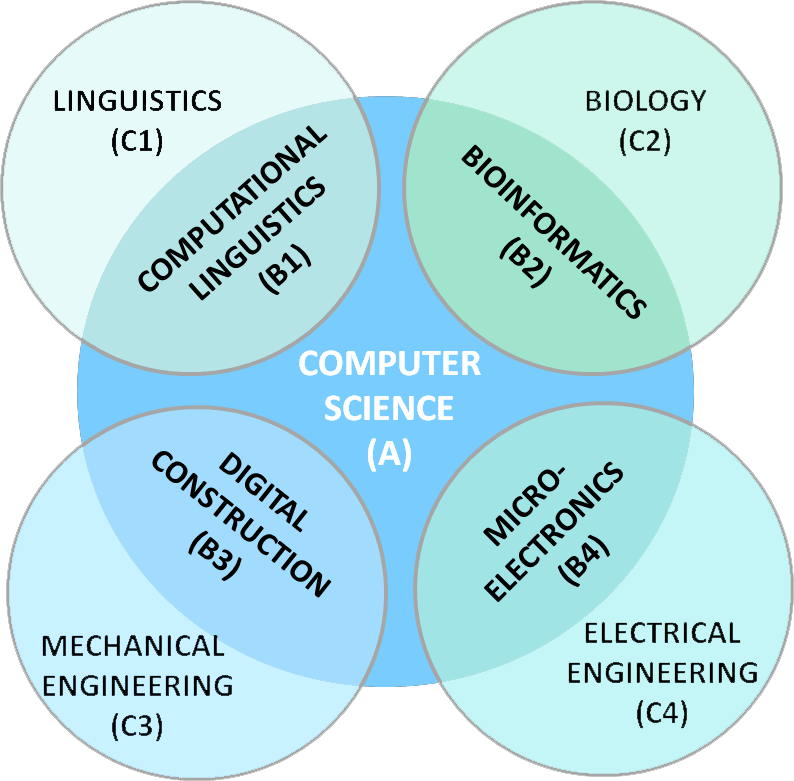
SciTex enthält die folgenden Subkorpora:
- Informatik (A Subkorpus)
- vier Kontaktdisziplinen (B Subkorpus)
(Computerlinguistik, Bioinformatik, digitale Konstruktion und Mikroelektronik) - vier Grunddisziplinen (C Subkorpus)
(Linguistik, Biologie, Maschinenbau und Elektrotechnik)
SciTex ist unterteilt in DaSciTex (frühe 2000er) und SaSciTex (1970er/1980er). Der gesamte Korpus umfässt etwa 34 Millionen Tokens.
Der Korpus besteht aus:
- zwei kleinen, bereinigten Korpora mit jeweils etwa 1 Millionen Tokens für grammatische Analysen (einer für die 70/80er und einer für die frühen 2000er) und
- zwei große Korpora (70/80er und früher 2000er) mit jeweils 17 Millionen Tokens für die lexikalischen Analysen (die kleinen Korpora sind in den großen Korpora enthalten)
Projektbezogene Publikationen
Teich, E., Degaetano-Ortlieb, S., Fankhauser, P., Kermes, H., and Lapshinova-Koltunski, E. (2014). The Linguistic Construal of Disciplinarity: A Data Mining Approach Using Register Features. Journal of the Association for Information Science and Technology (JASIST). To appear.
Degaetano-Ortlieb, S., Fankhauser, P., Kermes, H., Lapshinova-Koltunski, E., Ordan, N. and Teich, E. (2014). Data Mining with Shallow vs. Linguistic Features to Study Diversification of Scientific Registers. Proceedings of the 9th edition of the Language Resources and Evaluation Conference (LREC 2014). Reykjavik, Iceland. URL: www.lrec-conf.org/proceedings/lrec2014/pdf/291_Paper.pdf
Degaetano-Ortlieb, S. and Teich, E. (2014). Register diversification in evaluative language: The case of scientific writing. In Geoff Thompson and Laura Alba-Juez (eds). Evaluation in Context. John Benjamins Publishing Company, pp. 241-258. URL: benjamins.com
Fankhauser, P., Knappen, J. and Teich, E. (2014). Exploring and Visualizing Variation in Language Resources. Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC'14). Reykjavik, Iceland. URL: http://www.lrec-conf.org/proceedings/lrec2014/pdf/185_Paper.pdf
Fankhauser, P., Kermes, H. and Teich, E. (2014). Combining Macro- and Microanalysis for Exploring the Construal of Scientific Disciplinarity. Digital Humanities Conference. Lausanne, Switzerland. URL: dharchive.org/paper/DH2014/Poster-126.xml
Degaetano-Ortlieb, S., Kermes, H., Lapshinova-Koltunski, E. and Teich, E. (2013). SciTex - A Diachronic Corpus for Analyzing the Development of Scientific Registers. In Bennett, P., Durrell, M., Scheible, S. and Whitt, R. J., eds. New Methods in Historical Corpus Linguistics. Corpus Linguistics and Interdisciplinary Perspectives on Language - CLIP, Volume 3. Tübingen, Narr.
Degaetano-Ortlieb, S., Kermes, H. and Teich, E. (2013). The notion of importance in academic writing: detection, linguistic properties and targets. Proceedings of the 2nd Workshop on Practice and Theory of Opinion Mining and Sentiment Analysis (PATHOS). Darmstadt, Germany.
Degaetano-Ortlieb, S., Kermes, H., Lapshinova-Koltunski, E. and Teich, E. (2013). Automatic text classification for diachronic register analysis. 24th European Systemic Functional Linguistics Conference and Workshop (ESFLCW2013). Coventry, UK.
Degaetano-Ortlieb, S., Lapshinova-Koltunski, E., Kermes, H. and Teich, E. (2013). Procedures for Automatic Corpus Enrichment. Corpus Linguistics. Lancaster, UK.
Degaetano-Ortlieb, S. and Teich, E. (2013). A methodology to analyze evaluation across scientific disciplines - feature detection, extraction and annotation. Corpus Linguistics - Workshop Evaluative Language and Corpus Linguistics. Lancaster, UK.
Degaetano-Ortlieb, S. and Teich, E. (2013). Detection, extraction and annotation of evaluative expressions in a corpus of academic writing. Deutsche Gesellschaft für Sprachwissenschaft (DGfS) Sektion Computer Linguistic - Postersession. Potsdam, Germany.
Lapshinova-Koltunski, E., Degaetano-Ortlieb, S., Kermes, H. and Teich, E. (2013). Linguistic evolution of conjunctive relations in emerging scientific registers. In: F. Poppi and W. Cheng (eds). The three waves of globalization: winds of change in Professional, Institutional and Academic Genres. Cambridge Scholars Publishing, Cambridge, UK.
Lapshinova-Koltunski, E., Degaetano-Ortlieb, S., Kermes, H. and Teich, E. (2013). Usefulness of Corpora Enriched with Annotations on Abstract Linguistic Levels. Genre- and Register-related Text and Discourse Features in Multilingual Corpora. Brussels, Belgium.
Teich, E., Degaetano-Ortlieb, S., Kermes, H. and Lapshinova-Koltunski, E. (2013). Scientific registers and disciplinary diversification: a comparable corpus approach. Proceedings of 6th Workshop on Building and Using Comparable Corpora (BUCC). Sofia, Bulgaria.
Degaetano-Ortlieb, S., Lapshinova-Koltunski, E. and Teich, E. (2012). Domain-specific variation of sentiment expressions: exploring a model of analysis for academic writing. 1st Workshop on Practice and Theory of Opinion Mining and Sentiment Analysis (PATHOS) at Konvens2012. Vienna.
Degaetano-Ortlieb, S., Lapshinova-Koltunski, E. and Teich, E. (2012). Feature Discovery for Diachronic Register Analysis: a Semi-Automatic Approach. Proceedings of the LREC2012. Istanbul.
Kermes, H. (2012). Formulaic expressions: in this paper but where? Proceedings of ICAME 33. Leuven.
Kermes, H. (2012). A methodology for the extraction of information about the usage of formulaic expressions in scientific texts. Proceedings of LREC 2012. Istanbul.
Kermes, H. and Teich, E. (2012). Formulaic expressions in scientific texts: Corpus design, extraction and exploration. Lexicographica, Volume 28(1). De Gruyter, pages 99-120. URL: http://www.degruyter.com/view/j/lexi.2012.28.issue-1/lexi.2012-0007/lexi.2012-0007.xml?format=INT
Lapshinova-Koltunski, E., Teich, E. and Degaetano-Ortlieb, S. (2012). Tracing 'hybridity' in academic discourse: a corpus-based approach. Proceedings of the European Systemic Functional Linguistics Conference and Workshops (ESFLCW 2012). Bertinoro.
Lapshinova-Koltunski, E., Teich, E. and Degaetano-Ortlieb, S. (2012). Terminology now and then: changes across periods in academic writing. Proceedings of the ICAME 33. Leuven.
Lyding, V., Lapshinova-Koltunski, E., Degaetano-Ortlieb, S., Dittmann, H. and Culy, C. (2012). Visualising Linguistic Evolution in Academic Discourse. Proceedings of the EACL 2012. Avignon.
Teich, E., Degaetano-Ortlieb, S., Lapshinova-Koltunski, E. and Kermes, H. (2012). Register contact: an exploration of recent linguistic trends in the scientific domain. Proceedings of Historical Corpora 2012. Frankfurt.
Bartsch, Sabine, and Elke Teich, 2011. Register profiling of scientific texts: Experiences in linguistic description and corpus-based methods. ICAME32: Trends and Traditions in English Corpus Linguistics, In Honour of Stig Johansson. 127-128. Oslo, Norway. 1-5 June.
Bartsch, Sabine, and Elke Teich, 2011. Register Profiling for Highly Specialized Domains: Methods and Techniques. Anglistentag 2011, Sektion 'Approaches to Linguistic Variation'. Freiburg Brsg., Germany. September.
Bartsch, Sabine, Teich, Elke, Tragl, Christoph, 2011. Patterns of cohesion in informationally dense texts. Corpus Linguistics (CL2011). Birmingham. 20-22 July.
Degaetano-Ortlieb, Stefania, Hannah Kermes, Ekaterina Lapshinova-Koltunski and Elke Teich, 2012. SciTex – A Diachronic Corpus for Analyzing the Development of Scientific Registers. In: P. Bennett, M. Durrell, S. Scheible and R. J. Whitt, editors. Corpus Linguistics and Interdisciplinary Perspectives on Language - CLIP, Vol. 2. New Methods in Historical Corpus Linguistics. Narr. Tübingen, Germany.
Degaetano-Ortlieb, Stefania, Ekaterina Lapshinova-Koltunski, Elke Teich, 2012. Feature Discovery for Diachronic Register Analysis: a Semi-Automatic Approach. In Proceedings of the LREC-2012. Istanbul. 21-27 May.
Degaetano, Stefania, and Elke Teich, 2011. The lexico-grammar of stance: an exploratory analysis of scientific texts. In: St. Dipper and H. Zinsmeister, editors. Bochumer Linguistische Arbeitsberichte 3 - Beyond Semantics: Corpus-based Investigations of Pragmatic and Discourse Phenomena. 23-25 February.
Degaetano, Stefania, Teich, Elke, 2011. Exploring a semi-automatic approach for the analysis of interpersonal meaning in large corpora. International Systemic Functional Linguistics Conference (ISFC38). Lissabon. 25-29 July.
Degaetano, Stefania, 2011. Evaluative options and their choice - modal adjuncts vs. evaluative patterns in academic writing. International Evaluation Conference 2011 (IntEval). Madrid, Spain. October.
Degaetano, Stefania, 2011. Evaluation across scienti c disciplines - a corpus-based analysis. Corpus Linguistics (CL2011). Birmingham. 20-22 July.
Kermes, Hannah, 2012. Methodology for the extraction of information about the usage of formulaic expressions in scientific texts. In Proceedings of the LREC 2012. June.
Kermes, Hannah, 2012. Formulaic expressions: in this paper but where? In Proceedings of the ICAME 33. May.
Kermes, Hannah, 2011. Usage and function of formulaic expressions in scientific texts. Corpus Linguistics 2011. 86-87. Birmingham, UK. July.
Kermes, Hannah and Elke Teich. Formulaic expressions in scientific texts: Corpus design and extraction pipeline. Lexicographica. to appear.
Lapshinova-Koltunski, Ekaterina, Stefania Degaetano-Ortlieb, Elke Teich and Hannah Kermes, 2012. Usefulness of Corpora Enriched with Annotations on Abstract Linguistic Levels. In Proceedings of Genre- and Register-related Text and Discourse Features in Multilingual Corpora. 11-12 January.
Lapshinova-Koltunski, Ekaterina, Elke Teich and Stefania Degaetano-Ortlieb, 2012. Terminology now and then: changes across periods in academic writing. In Proceedings of the ICAME 33. May.
Lapshinova-Koltunski, Ekaterina, Elke Teich and Stefania Degaetano-Ortlieb, 2012. Tracing 'hybridity' in academic discourse: a corpus-based approach. In Proceedings of the ESFLCW2012. July.
Lapshinova, Ekaterina, Degaetano, Stefania, Teich, Elke, 2011. Interdisciplinarity in academic discourse - a corpus-based analysis. Interdisciplinary Linguistics Conference (ILinC2011). Belfast. 14-15 Oktober.
Lyding, Verena, Ekaterina Lapshinova-Koltunski, Stefania Degaetano-Ortlieb, Henrik Dittmann and Christopher Culy, 2012. Visualising Linguistic Evolution in Academic Discourse. In Proceedings of the EACL2012. Avignon, France. 23-27 April.
Teich, Elke, Ekaterina Lapshinova, Stefania Degaetano, 2012. Terminology now and then: changes across periods in academic writing. In Proceedings of the ICAME-33. Leuven. June.
Teich, Elke, Ekaterina Lapshinova, Hannah Kermes and Stefania Degaetano, 2011. Linguistic evolution of emerging scientific registers. Clavier2011. Modena, Italy. November.